Too Long; Don’t Watch
二二八連假,我整理了一下手邊囤積的各種,還沒時間或是懶得看的教學影片。包含了各大 Conference,或是路邊撿來的一些課程內容。點開這些影片,雖然內容跟標題都非常吸引人,不過常常出現奇怪的印度口音造成理解困難 QQ。而總計數百、數千小時的影片量應該是不可能在有生之年有辦法看完的,再加上許多影片並沒有提供原始的 PPT 檔案 QQ。
因此,我寫了一個腳本來透過 GPT 3 解決這個問題!透過 GPT3 的 AI 引擎來自動地幫每一頁的簡報進行 Summarize。
Repo 載點:https://github.com/stevenyu113228/TL-DW
在腳本中,首先我透過 ffmpeg 將影片截圖成每秒一張的照片,接下來使用 UQI (Universal image Quality Index) 區分出不同的圖片,並將圖片透過 Tesseract 進行 OCR 轉換成文字;同一時間,把影片的聲音軌給分離出來,並依照截圖的時間點進行切割,即可取得每一頁投影片所對應的語音內容,再把語音內容給送入 Google 的語音轉文字服務,取得每一頁講者的語音。
有了每一頁的 OCR 結果以及講者的語音轉文字,接下來就可以由 AI 出面了!我使用了目前最夯的 OpenAI GPT-3 text-davinci-003 模型,並使用以下咒語產出 Summary。
以下是一段課堂上投影片的語音轉文字,以及其對應講義的 OCR 資料,請忽視 OCR 的錯誤及簡報 header/footer。並使用繁體中文統整該頁面之內容,專有名詞部分請盡量保留使用英文\n\n語音轉文字:```\n{voice}\n```\n\n投影片 OCR:```{ocr}```\n\n統整結果:
最終,再把結果透過 Python 的 docx 輸出成完整報告,這樣下來只需要不到原始影片三分之一的時間,就可以讀完整份影片的內容,而如果逐字稿跟 AI 對於某段的總結有點奇怪時,也可以直接從報告上取得該頁面的時間,自己切回去影片重新查看!
不過 OpenAI 的 API 是需要付費的,但它有 18 美元的試用額度,我自己實驗下來,一個 30 分鐘的教學影片約需要花費 0.3~0.7 美元,我認為是非常划算 & 值得的!
而轉換的時間有一點長,其主要的時間都耗在 OpenAI 的 API 以及 Google 的語音轉文字 API 上,不確定把這段改成多執行序會不會出事,畢竟 API Server 可能會有 Rate Limit,目前整體下來的轉換時間大約等於影片時間。
目前這個腳本僅支援英文語音 + 英文簡報,不過這些語音轉文字、 OCR 其實都是有支援中文的,正常來說只需要修改程式碼中的語言部分就可以動,不過目前我還沒有做相關的測試。
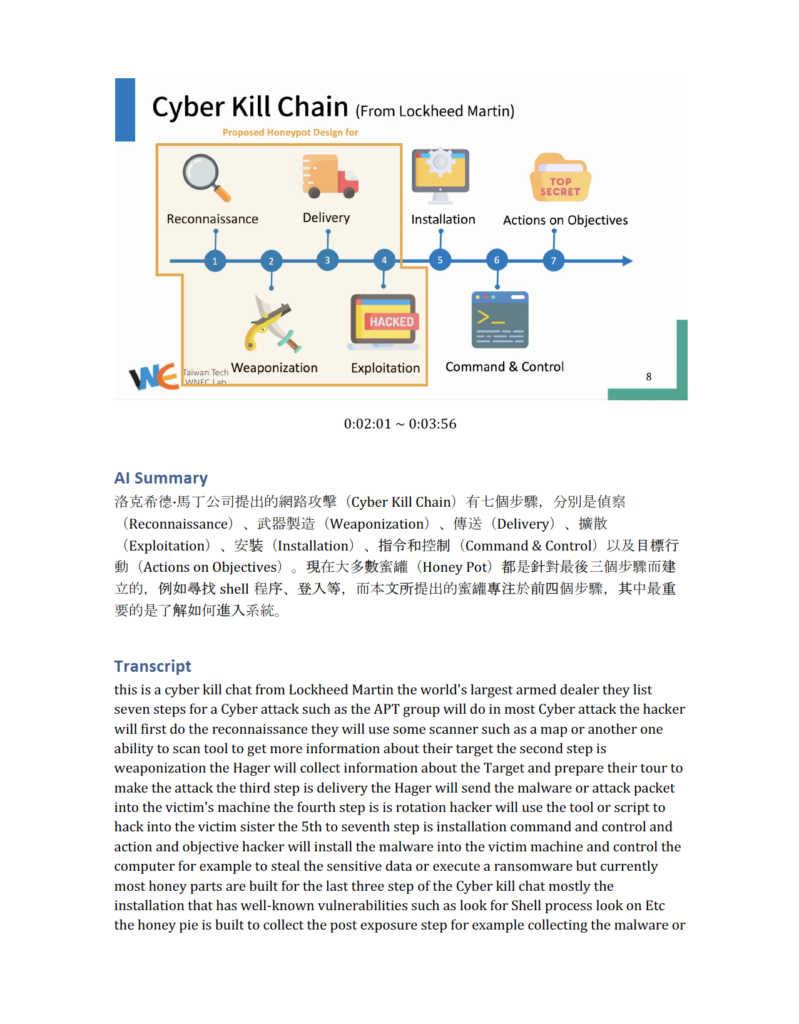
結果 Demo : 使用我這個月在日本東京 SECCON / BSides Tokyo 的演講其中一頁作為範例,產出的結果如下圖: